This note follows the teaching of CSU33061 Artificial Intelligence I in TCD. Some of the codes and graphs are adapted from the lecture slides (Tim, 2024).
The note is friendly for those who didn’t take CSU34011 Symbolic Programming, i.e. you are not so familiar with Prolog.
Finite State Machine
Finite state machine (FSM) is a model for any system that has a limited number of conditional states of being.
A finite state automation has 5 parts (ref: https://www.cs.montana.edu/webworks/projects/oldjunk/theory/contents/chapter002/section002/green/page002.html):
- A set of states
- A designed start state from the set of states
- A designed set of accepting states
- A set of transitions between states
- A set of input symbols
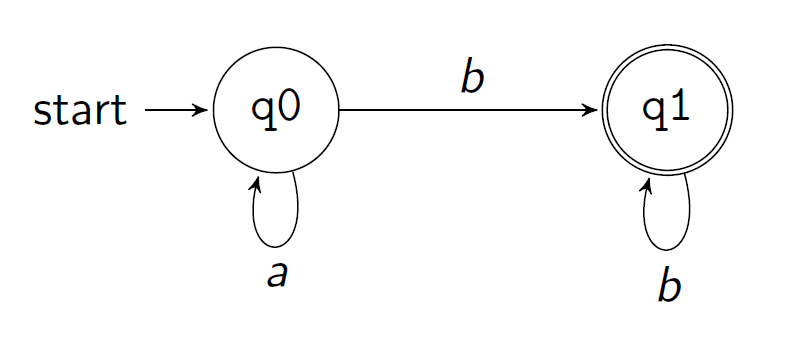
A circle (〇) represents a state, while a double circle (◎) is the final or accepting state.
In Prolog, we can represent a FSM M by a triple [Trans, Final, Q0] where:
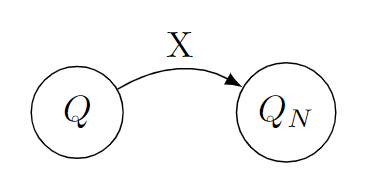
Transis a list of triples[Q, X, Qn]such that the machineMmay, at the state ofQ, seeing a symbol ofX, transform toQn.
That is
[[q0,a,q0],[q0,b,q1],[q1,b,q1]]in the example.-
Finalis a list ofM‘s final (accepting) states.That is
[q1]in the example. -
Q0isM‘s initial state.That is
q0in the example.
Example: Convert a String to a FSM
Encode strings as lists; e.g. 102 as [1,0,2].
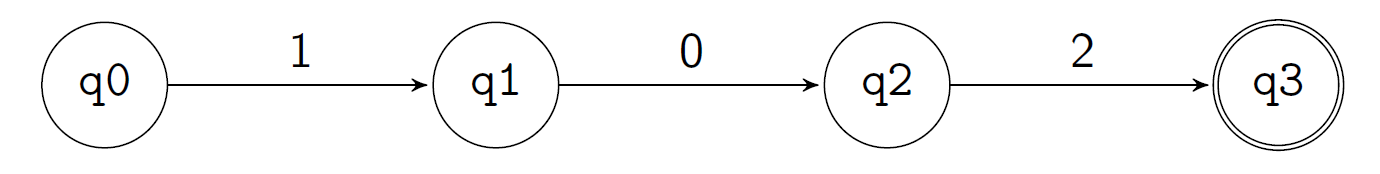
% string2fsm(+String, ?TransitionSet, ?FinalStates)
string2fsm([], [], [q0]).
string2fsm([H|T], Trans, [Last]) :- mkTL(T, [H], [[q0, H, [H]]], Trans, Last).
% mkTL(+More, +LastSoFar, +TransSoFar, ?Trans, ?Last)
mkTL([], L, Trans, Trans, L).
mkTL([H|T], L, TransSoFar, Trans, Last) :- mkTL(T, [H|L], [[L,H,[H|L]]|TransSoFar], Trans, Last).
string2fsm
string2fsm is a predicate that transform a string into a FSM transition set.
string2fsm(+String, ?TransitionSet, ?FinalStates) (line1)
It takes in a string, and returns a TransitionSet and a FinalStates that defines a FSM.
We note the input of a predicate/function with the symbol of
+and output as?as a programming convention in Prolog.Similar to Haskell, Prolog supports pattern matching. If the first definition is not fit, then it goes to the second one. The predicate is signed as
string2fsm/3as it takes 3 arguments.
- When the string is empty, the transition set is empty, and the initial state is
q0. (line2) -
When the string is not empty, the predicate take the first/tail numbers in the list, then calls
mkTLto create the TransitionSet and FinalStates. (line 3)Similar to Haskell,
[H|T]is a way of getting the head and remaining part of a list. E.g. [1,2,3,4] -> H=1, T=[2,3,4].
mkTL
mkTL(+More, +LastSoFar, +TransSoFar, ?Trans, ?Last) (line 4)
mkTL is a predicate that converts an input list to a TransitionSet and a FinalStates that defines a FSM.
mkTL([], L, Trans, Trans, L).(line 5)When the first parameter,
+More(i.e. that remaining list that is not processed), is empty, this means that the whole process is finished. In this case,Transis output as the Trans rules that had been obtained before, stored inTransSoFar, whileLastis the finalLastSoFarlist.-
mkTL([H|T], L, TransSoFar, Trans, Last) :- mkTL(T, [H|L], [[L,H,[H|L]]|TransSoFar], Trans, Last).(line 6)Otherwise in normal situations,
mkTLis recursive, with parameters:[H|T], the current input list, whereHis the head andTis the tailL, the current last stateTransSoFar, the list of all convert rules obtainedTrans, output of the final trans rules listLast, output of the final state
The predicate works as: Combine the head element
Hwith the last stateL, and transforms to the new state[H|L]. This rule is presented as[L,H,[H|L]]. The new rule is saved to theTransSoFarrule lists, as[[L,H,[H|L]]|TransSoFar]. The predicate then calls itself with the remaining string,T, and the most recent last state in last states listL.The new state
[H|L]is a list so it can store the history of transforms.E.g. The initial state is
[q0], with the input string of[1,0,2].Initial state: [q0]
Input
1, the state changes to:[1, q0]Input
0, the state changes to:[0,1,q0]Input
2, the state changes to:[2,0,1,q0]
If the initial state q0 is empty, str2fsm can be simplified as:
str2fsm(String, Trans, [Last]) :- mkTL(String, [], [], Trans, Last).
Running results
To run the code in Prolog, just store the predicates and enter the query,
E.g. ?- string2fsm([1,0,2], Trans, Last)., the result goes as:
Last = [[2, 0, 1]],
Trans = [[[0, 1], 2, [2, 0, 1]],
[[1], 0, [0, 1]],
[q0, 1, [1]]]
Which means:
- the final last state is
[2,0,1](the reverse of input) - the transition set contains
- trans the state from
q0to[1]when seeing1 - trans the state from
[1]to[0,1]when seeing0 - trans the state from
[0,1]to[2,0,1]when seeing2
- trans the state from
Accept
a 4-ary predicate that is true exactly when [Trans,Final,Q0] is a fsm that accepts String (encoded as a list).
% accept(+Trans,+Final,+Q0,?String)
accept(_,Final,Q,[]) :- member(Q, Final).
accept(Trans,Final,Q,[H|T]) :- member([Q, H, Qn], Trans), accept(Trans,Final,Qn,T).
% Where the user defined predicate `member` is:
member(X,[X|_]).
member(X,[_|L]) :- member(X,L).
accept(_,Final,Q,[]) :- member(Q, Final).The basic of recursion. Stops when current state
Qis a member of all accepting statesFinal, and there’s no elements in the input string.-
accept(Trans,Final,Q,[H|T]) :- member([Q, H, Qn], Trans), accept(Trans,Final,Qn,T).This is the process of recursion. Check the first item in the list if there is one transform from the current state
Q(or start atQ0), seeing the first item inString(that is[H|T]), and matches a new state ofQn, is in theTranslist. If there is, then recursively check the remaining string as noted asT, with the new stateQnobtained from last step.
E.g.: an FSM accepting a* a b*
a* a b*is a FSM that: takes one or morea, then continues to zero or moreb.
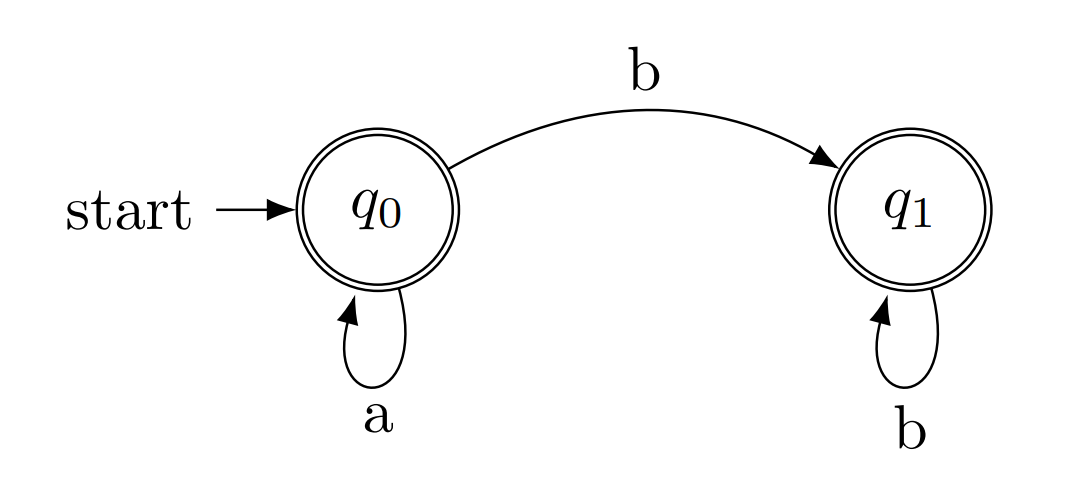
Trans:
trans(q0,a,q0).
trans(q0,a,q1).
trans(q1,b,q1).
Final:
final(q1).
Accept:
accept(Q,[]) :- final(Q).
accept(Q,[H|T]) :- trans(Q,H,Qn), accept(Qn,T).
Quests:
?- accept(q0,[a,b]).
true
?- accept(q0,[a,b,b,a]).
false
Search
search(Node) :- goal(Node).
search(Node) :- move(Node,Next), search(Next).
The function returns true. if the current Node is the goal (line 1). Otherwise, set the current Node to the next node, then search the Next Node as a recursion (line 2).
Graph modeling
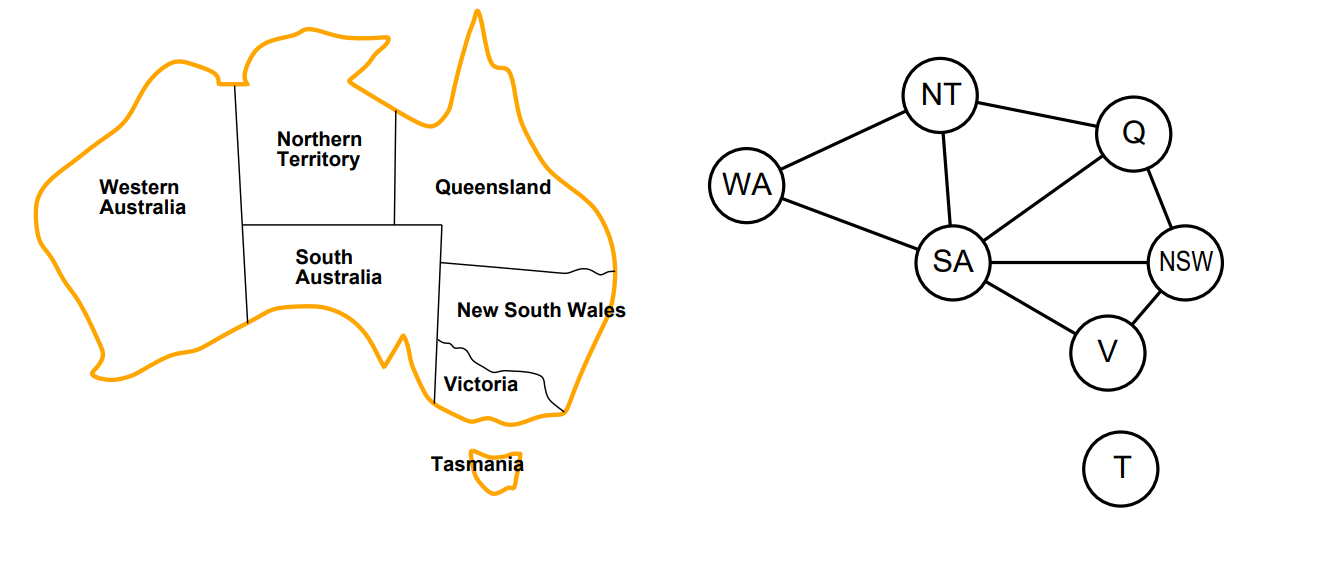
Graph arc representation
A way to store all graph knowledge is:
ar(wa,nt). ar(nt,q). ar(q,nsw).
ar(nsw,v). ar(wa,sa). ar(sa,nsw).
ar(nt,sa). ar(sa,v). ar(sa,q).
And convert from directed to undirected graph:
arc(X,Y) :- ar(X,Y) ; ar(Y,X).
Relate to Search:
search(Node) :- goal(Node).
search(Node) :- move(Node,Next), search(Next).
Here move is replaced by arc.
search(Node) :- goal(Node).
search(Node) :- arc(Node,Next), search(Next).
Example: accept(Trans, Final, Q0, String) Node as [Q, UnseenString]
goal([Q,[]],final) :- member(Q,Final).
arc([Q,[H|T]],[Qn,T],Trans) :- member([Q,H,Qn],Trans).
goal: if there’s no more members in the unseen list, and current state Q is one of the final states, then we say Q has reached the goal.
% arc(+StateAndInput, -NewStateAndRemainingInput, +Transitions) : -.
arc: if there is a transition of [Q,H,Qn] in Trans, then there’s an arc, which turns the current state Q and current input [H|T] with trans [Q,H,Qn] to the new state and reaming list [Qn,T].
The search process
search(Node,Fi,_) :- goal(Node,Final).
search(Node,Fi,Tr) :- arc(Node,Next,Tr), search(Next,Fi,Tr).
accept(Tr,Fi,Q0,S) :- search([Q0,S],Fi,Tr).
Fi: final state; Tr: transition
search(Node,Final,_) :- goal(Node,Final).: if the Node is in the Final states, regardless of trans set Tr, search is complete.
search(Node,Fi,Tr) :- arc(Node,Next,Tr), search(Next,Fi,Tr).: Use arc to find the next item of current Node, then recursively apply search on it.
Knowledge Base (KB) and searching
Case without loop
i :- p,q.
i :- r.
p.
r.
q :- false.
?- i.
true.
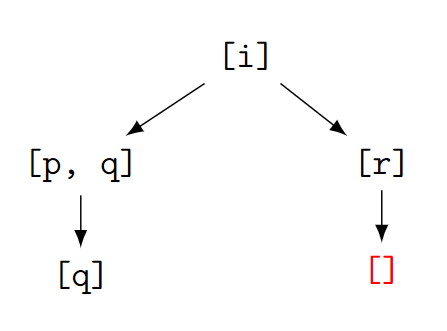
Case with loop
A Non-termination (due to poor choice) case.
i :- p, q.
i :- r.
p :- i.
r.
q :- false.
> i
Stack limit (0.2Gb) exceeded
Stack sizes: local: 0.2Gb, global: 20Kb, trail: 1Kb
Stack depth: 3,675,297, last-call: 50%, Choice points: 1,837,647
Probable infinite recursion (cycle):
[3,675,296] i
[3,675,294] i
KB representation
We can use a sequence of [Conclusion,Hypothesis]. E.g., p^q→i is denoted as [i,p,q].
Neighbors obtaining
arc([H|T],N,KB) :- member([H|B],KB), append(B,T,N).
[H|T] is the former list, while N is a next(neighbor) list. KB is a list of lists representing the knowledge base.
The predicates starts from the current list [H|T], then check if there exits any lists start with H in the KB. If there is, we append the remaining parts to the new list, as new parts means the new elements we need to prove for solving the problem. (Just similar as Move)
append(?List1, ?List2, ?List1AndList2)
E.g.:
?- append([a,b],[c],X). X = [a, b, c]. ?- append(A,[L],[a,b,c]). A = [a, b], L = c ; ?- append(X,[d,e],[a,b,c,d,e]). X = [a, b, c] ;
For example, if we have a knowledge base of [[i,p,q],[i,r],[p],[r]], i.e.
?- arc([i], N, [[i,p,q],[i,r],[p],[r]]).
N = [p, q]
This shows that, if we starts with i, we can obtain the neighbor of [b,c] from the KB as the first step.
Proving/Searching with KB
prove(Node,KB) :- goal(Node) ;
arc(Node,Next,KB), prove(Next,KB).
;meansORin Prolog, which plays the same role as pattern matching with two lines. In real practice, the pattern matching style is preferred.
The code means: if the current Node is the goal, then the whole process ends. Otherwise, we look for the neighbor of current (first) node, then iterate it.
goal([d]).
# here we use `write(B)` to track the searching path.
arc([H|T],N,KB) :- member([H|B],KB), append(B,T,N), write(N).
prove(Node,KB) :- goal(Node) ;
arc(Node,Next,KB), prove(Next,KB).
?- prove([a], [[a,b],[b,c],[c,d]]).
# [b][c][d]
true
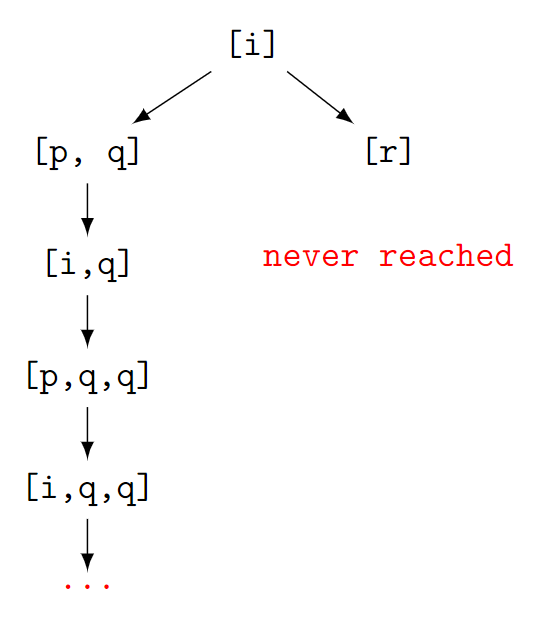
If there’s a infinite loop in the KB:
# we try to prove that `i` is true, so the goal is to solve all unknown items, to reach a list of blank.
goal([]).
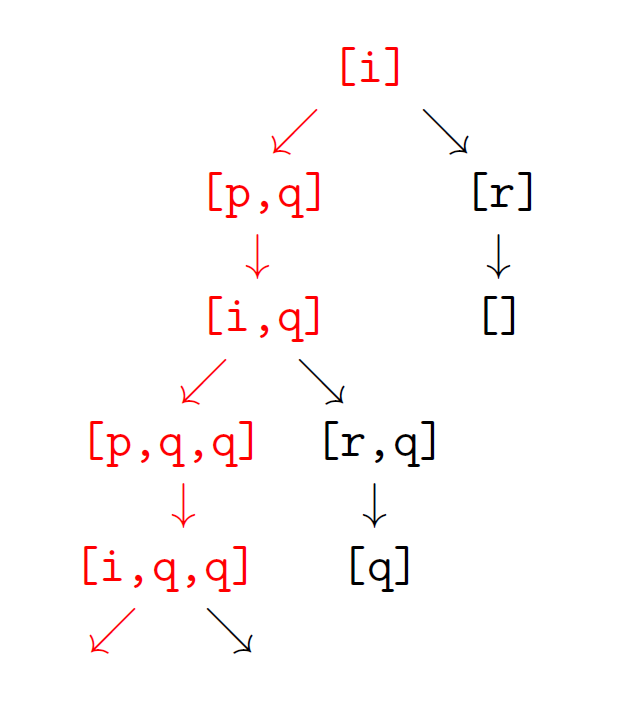
?- prove([i], [[i,p,q],[i,r],[p,i],[r]]).
# [p, q][i, q][p, q, q][i, q, q][p, q, q, q][i, q, q, q][p, q, q, q, q][i, q, q, q, q][p, q, q, q, q, q][i, q, q, q, q, q][p, q, q, q, q, q, q][i, q, q, q, q, q, q]...
We first got i, then i->p^q gives [p,q], then p->i gives [i,q], then [i->p^q] gives [p,q,q]…
(Just check the graph in [Case with loop](#Case with loop))
However, if we change the sequence by prioritizing [i,r], we got:
?- prove([i], [[i,r],[i,p,q],[p,i],[r]]).
# [r][]
true
As we first got i, then i->r gives [r], then [r|] gives [], which reaches the goal.
A simpler version of prove
If we just want to prove a statement is true, we just need to reach the goal of a empty current nodes list (like the last section). In this scenario we can rewrite the prove function as:
prove([],_).
prove([H|T],KB) :- member([H|B],KB), append(B,T,Next), prove(Next,KB)
Where prove stops and gives true when the current list is empty.
?- prove([i],[[i,p,q],[i,r],[p,i],[r]]).
Stack limit (0.2Gb) exceeded
Stack sizes: local: 0.2Gb, global: 46.6Mb, trail: 5.5Mb
Stack depth: 718,187, last-call: 0%, Choice points: 718,170
Possible non-terminating recursion:
[718,186] prove([length:359,080], [length:4])
[718,185] prove([length:359,080], [length:4])
This is called a Non-termination process. The search algorithm follows the red path.
## Determinization (do all)
Definition: A FSM [Trans, Final, Q0] such that:
for all [Q,X,Qn] and [Q,X,Qn'] in Trans, Qn=Qn',
is a deterministic finite automation (DFA).
This means that for any given state Q with an input signal X, there’s only one fixed output state Qn. This ensures that the performance of the automation is fixed with same inputs.
Fact: Every fsm has a DFA accepting the same language.
This is proved by Subset (powerset) construction.
arcD(NodeList,NextList) :- setof(Next, arcLN(NodeList,Next), NextList).
arcLN(NodeList,Next) :- member(Node,NodeList), arc(Node,Next).
goalD(NodeList):- member(Node,NodeList),goal(Node).
searchD(NL) :- goalD(NL); (arcD(NL,NL2), searchD(NL2)).
search(Node) :- searchD([Node]).
Didn’t fully understand it.
Blind searches: BFS and DFS
Frontier search
search(Node) :- frontierSearch([Node]).
frontierSearch([Node|_]) :- goal(Node).
frontierSearch([Node|Rest]) :-
findall(Next,arc(Node,Next),Children),
add2frontier(Children,Rest,NewFrontier),
frontierSearch(NewFrontier).
We use frontierSearch to search for a Node.
Searching process:
- Every time when going to a new node, we check if the current
Nodeis goal or not. - If not:
- we obtain the first
Nodein the frontier (with the remainsRest), and find all children/neighbors of the currentNode, save them as a listChildren - combine the
Restnodes in the original frontier with the new childrenChildren. This is not defined yet as different ways of combing two lists leads to different searching results (BFS/DFS). The combination result isNewFrontier. - apply
frontierSearchto the new frontierNewFrontier.
- we obtain the first
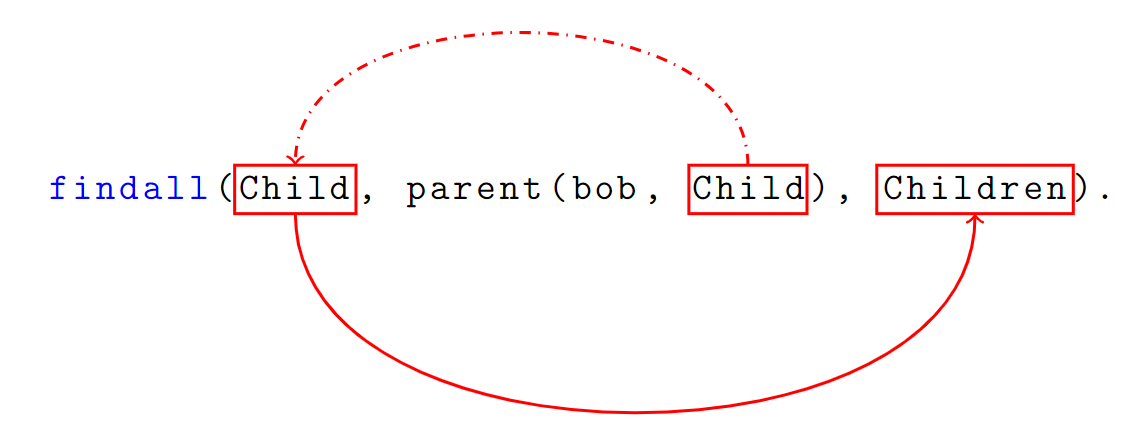
findall(+Template, :Goal, -Bag)
Template: A template of the things that you are trying to extract from the results.
Goal: A query condition to fit requiements.
List: Saves all results fromTemplatewhich fitsGoal.E.g.:
We got a list of parent & child relations:
parent(bob, alice). parent(bob, john). parent(alice, lisa). parent(john, dave).And we want to find out all children of bob:
?- findall(Child, parent(bob, Child), Children). Children = [alice, john]
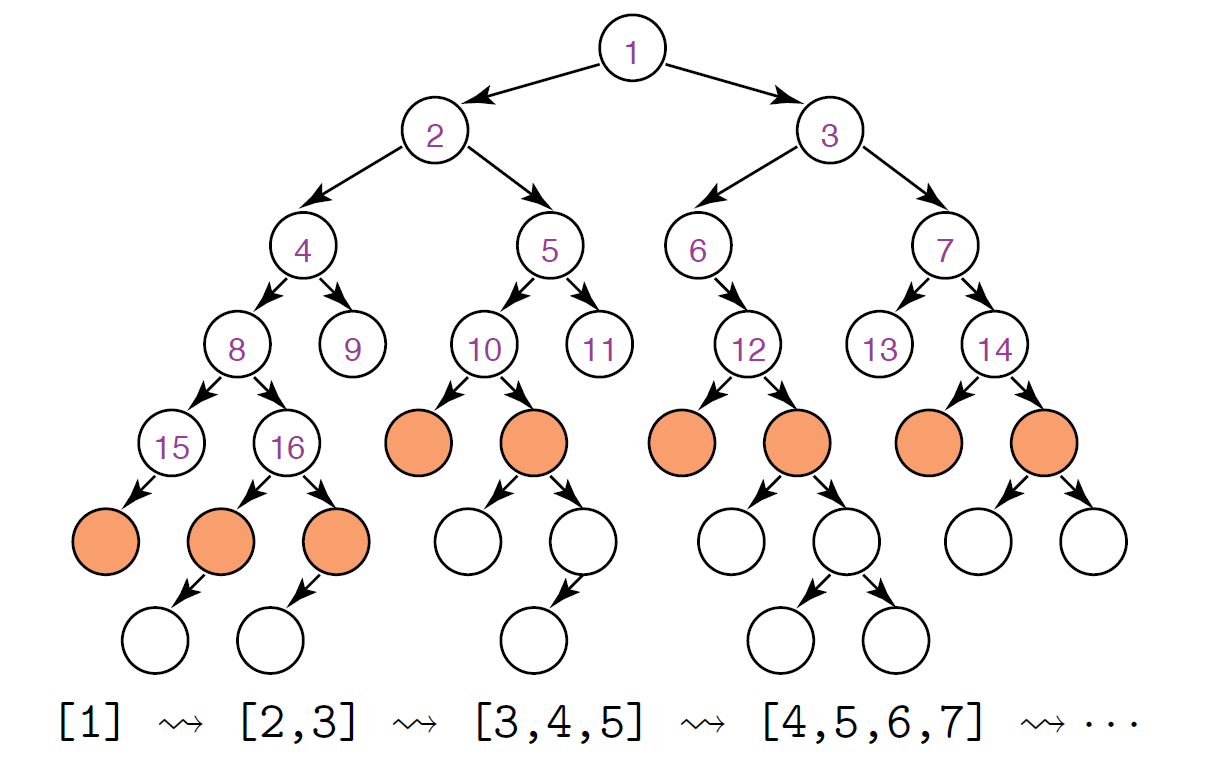
Breadth-first: queue (FIFO)
This is to put the new children at the end of the frontier.
# add2frontier(+Children,+Rest,-NewFrontier),
add2frontier(Children,[],Children).
add2frontier(Children,[H|T],[H|More]) :- add2frontier(Children,T,More).
- If there are no remaining nodes in the frontier, then the all new children is the new frontier.
- Otherwise, recursively append
ChildrenafterRest.
Actually this is similar to: append(Rest, Children, NewFrontier)
How the recursion works?
Take
add2frontier([c,d],[a,b],Result).as an example:
- 1
Chrildren=[c,d],Rest=[a|b]- 2 Then recursively call
add2frontierasadd2frontier([c,d],[b],More)- 3 This time,
Rest=[b|].- 4 Then recursively call
add2frontierasadd2frontier([c,d],[],More)- 5 Here we went to the basis of recursion
add2frontier(Children,[],Children)., as the second argument is a blank list. SoMoreis fixed as[c,d](since the first and the third argument are the same).- 6 Then we go back to step 4, where
Moreis[c,d], so theNewFrontieris[H|More]that is[b|More]i.e.[b,c,d]- 7 Then go back to step 2, where
Moreis[b,c,d]now, so theNewFrontieris[H|More]that is[a,b,c,d].
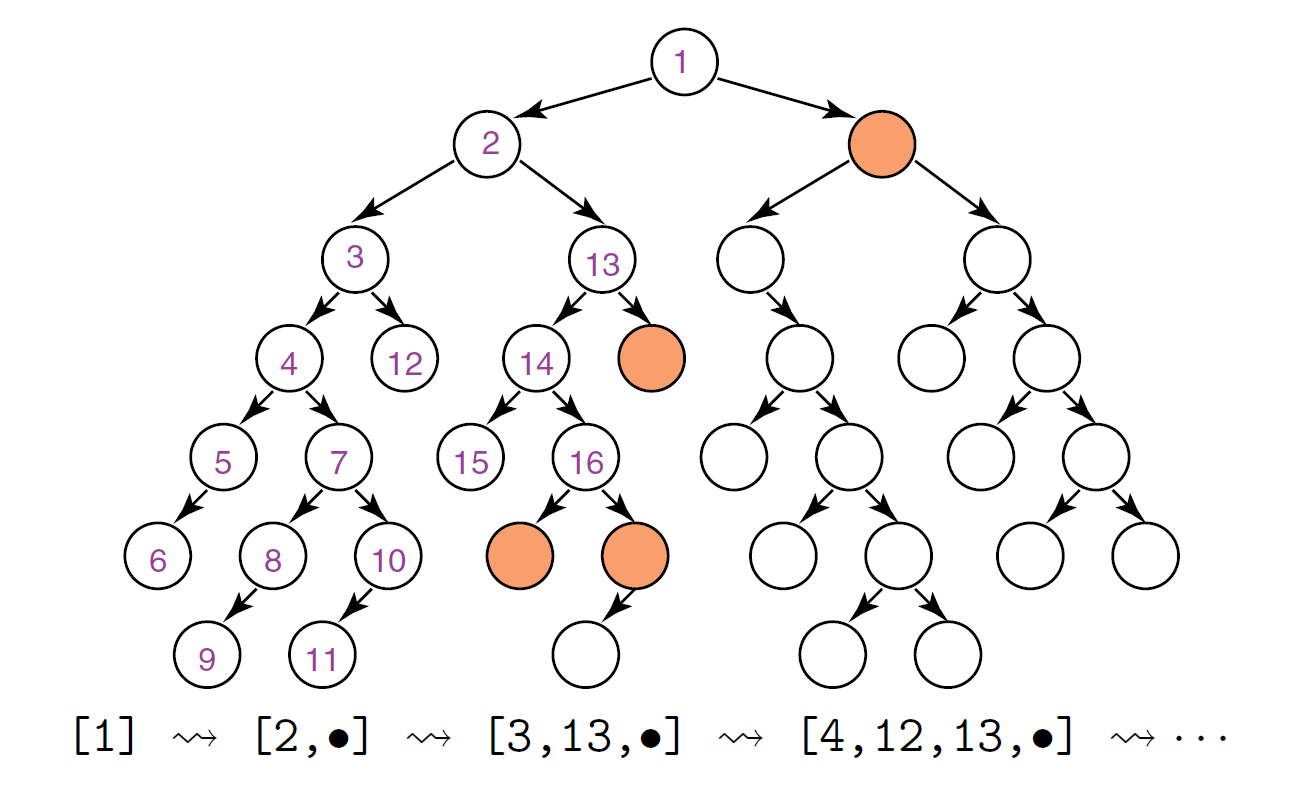
Depth-first: stack (LIFO)
This is to put the new children at the front of the frontier.
# add2frontier(+Children,+Rest,-NewFrontier),
add2frontier([],Rest,Rest).
add2frontier([H|T],Rest,[H|TRest]) :- add2frontier(T,Rest,TRest).
Similar to append(Children, Rest, NewFrontier).
Cut
Grammar
Cut is a way of pruning which disable backtracking in Prolog.
What is a backtrack?
For example, we have a predicate of
goal/1.goal(a). goal(b).This is also called as pattern matching in Haskell.
If we enter an query of
?- goal(b)., Prolog will first look into the first rulegoal(a)., with the result of false, then it tries to look into other rules, and reachedgoal(b), return that the result is true. The process of finding a false node and going back to the last state and looking for other rules is called asbacktrack.
We use ! to denote a cut in Prolog, which stops backtracking.
E.g.: The normal predicate search(X) without cut is:
item(a).
item(b).
search(X) :- item(X).
?- search(X).
X = a;
X = b.
If we add cut after the first item:
item(a).
item(b).
search(X) :- item(X),!.
?- search(X).
X = a.
Another example:
animal(dog).
animal(cat).
friendly(cat).
pet(X) :- animal(X), !, friendly(X).
?- pet(X).
false
This is because once Prolog found that dog is an animal, it then check if it’s friendly or not, and can not go back to check any other animals.
Therefore, for the [KB Loop case](#Case with loop) introduced before, it could be adapted with a cut to avoid infinite loop:
i :- p,!,q.
i :- f.
p.
r.
?- i.
false
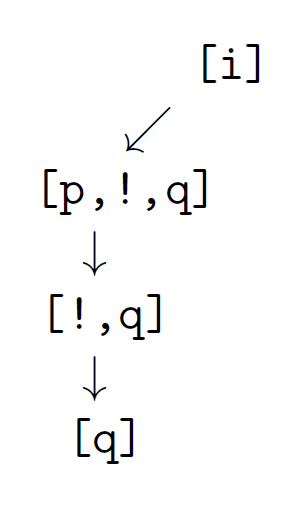
Cut and Search
prove([], ).
prove(Node,KB) :- arc(Node,Next,KB), prove(Next,KB).
fs([[]| ], ).
fs([Node|Rest],KB) :- findall(X,arc(Node,X,KB),Children), append(Children,Rest,NewFrontier), fs(NewFrontier,KB).
For DFS: cut should not be used otherwise we can only search one subtree.
Cut via frontier depth-first search:
fs([[]|_],_).
fs([[cut|T]|_],KB)) :- fs([T],KB).
fs([Node|Rest],KB) :- Node = [H| ], H\== cut, findall(X,arc(Node,X,KB),Children), append(Children,Rest,NewFrontier), fs(NewFrontier,KB).
if(p,q,r) :- (p,!,q); r.
# contra (p,q);r
negation-as-failure(p) :- if(p,fail,true).
fs([[]|_],_): stops searching when there’s nothing in the list.fs([[Cut|T]|_], KB)) :- fs([T],KB).: if the first node in the frontier is cut, then skip this node and go to the following nodesT.fs([Node|Rest],KB) :- Node = [H| ], H=== cut, findall(X,arc(Node,X,KB),Children), append(Children,Rest,NewFrontier), fs(NewFrontier,KB).: Take the firstNodefrom the frontier list, and decompose it again from to take the first itemH, ifHis notcut, then find all related children toChildren, and append them to the start of the previous frontier listRest, then recursively do the search.-
if(p,q,r) :- (p,!,q); r.ifpthenqelser. negation-as-failure(p) :- if(p,fail,true).: ifpis true thennegation-as-failure(p)is false; ifpis false thennegation-as-failure(p)is true.
Exercise
Ex from Lec 3 Search
Question
Suppose a positive integer Seed links nodes 1,2,… in two ways
arc(N,M,Seed) :- M is N*Seed.
arc(N,M,Seed) :- M is N*Seed + 1.
E.g. Seed=3 gives arcs (1,3), (1,4), (3,9), (3, 10)...
Goal nodes are multiples of a positive integer Target
goal(N,Target) :- 0 is N mod Target.
e.g. Target=13 gives goals 13, 26, 39..
Modify frontier search to define predicates
breadth1st(+Start, ?Found, +Seed, +Target)
depth1st(+Start, ?Found, +Seed, +Target)
that search breadth-first and depth-first respectively for a Target-goal node Found linked to Start by Seed-arcs.
Answer
Heuristic / A*
Recall the standard frontier search in Prolog:
frontierSearch([Node|Rest]) :- goal(Node); (findall(Next, arc(Node,Next), Children), add2frontier(Children, Rest, NewFrontier), frontierSearch(NewFrontier)).
With append(Children, Rest, NewFrontier) for DFS and append(Rest, Children, NewFrontier) for BFS, to be defined in add2frontier.
To refine frontier search, we try to let the Head in NewFrontier=[Head|Tail] no worse than any in Tail (i.e. we are trying to use the best node from all neighbors).
How to define a Node1 is no worse than Node2?
Node1costs no more thanNode2: minimum search cost (=BFS if every arc costs 1) (uniform cost search)Node2is deemed no further from a goal node thanNode2: best first search (=DFS for heuristic ∝ depth$^{-1}$) (greedy search)- some mix of the former two: **A***
Arc costs: including distance, time, space, etc.
Best-first search / Greedy search
Form NewFrontier = [Head|Tail] such that h(head)<=h(Node) for every Node in Tail. That is, every time we pick the one with least heuristic value from all neighbor nodes.
Heuristic
h(Node)= estimate the minimum cost of a path from Node to a goal node.
Example:
- FSM accept where
node=[Q,String]and everyarccosts 1h([Q, String]) = length(String) -
Prolog search where node = list of propositions to prove, and every arc costs 1
h(List) = length(List) -
Node = point on a Euclidean plane, cost = distance between nodes, goal is a point
Gh(Node) = straight-line distance to G -
estimate assuming lots of arcs (simplifying the problem)??
Min-cost (UCS)
$cost(n_1 \cdots n_k)=\sum^{k-1}{i=1}cost(n_i,n{i+1})$
To find the route with the lowest path cost.
A*
$solution = start \dots n \dots goal$
$f(start \dots n) = cost(start \dots n)+h(n) $
Ensure Frontier=[Head|Tail] where Head has minimal f.
- $h(n)=0$ for every $n \rightarrow $ min cost/UCS (uniform cost search)
- $cost(start\cdots n)=0$ for every $n \rightarrow$ best-first (disregarding the past) i.e. greedy search
If we assume between all connected nodes are
1, then if we search by minimizing the sum, it results to BFS (as try to search the nodes with less distance first), if maximizing the sum (searching the nodes with greatest distance first), it results to DFS.
A* tweaks breadth-first assuming:
- arc-costs > 0
- h under-estimates the cost of a path to a goal
- finite branching
Min-cost becomes depth-first if arc-cost=-1 and h=0.
Admissibility
A* is admissible (under cost $h$) if it returns a solution of min cost whenever a solution exists.
3 conditions sufficient for admissibility:
- under-estimate: for every solution $n\dots goal$, $0\leq h(n)\leq cost(n\dots goal)$
- termination: for some $\epsilon > 0$, every arc costs $\geq \epsilon$
- finite branching: ${n’ | arc(n,n’)}$ is finite for each node $n$
MDP with graph
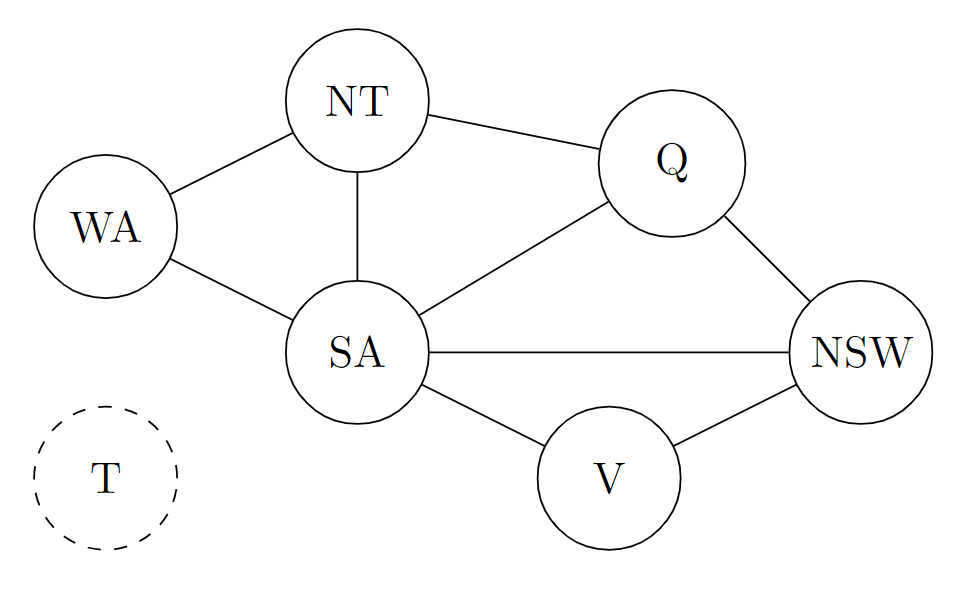
Distance set
We define:
$$
G_n \approx {nodes\ \text{with distance }n\text{\ from}\ G}
$$
$$
G_{n+1}:={s|(\exist s’ \in G_n)\ arc(s,s’))}-\bigcup^n_{i=1}G_i
$$
$G_n$ are the nodes who has distance $n$ from $G$, and $G_{n+1}$ are those nodes who connects with $G_n$ and has longer distances than $G_n$.
Hence we got:
$G_n:=G$, ${V}_0={V}$, ${V}_1={SA, NSW}$, ${V}_2={WA, NT, Q}$, ${V}_\infty={T}$
$$
d_G(s):=\begin{cases}
n & \text{if } s \in G_n \
\infty & \text{otherwise}
\end{cases}
$$
$d_G(s)$ is the distance from a specific node $s$ to the goal $G$. If $s$ is in the set $G_n$, then the distance from $s$ to $G$ is $n$.
Reward
To reach the goal $G$, we set a basic reward function: you will be rewarded if has reached the goal (set) , otherwise nothing.
$$
\delta_G(s):=\begin{cases}
1 & \text{if } s \in G \
0 & \text{otherwise}
\end{cases}
$$
And we are going to make it more complexed:
$$
r_G(s):=\begin{cases}
2^{-n} & \text{if } s \in G_n \
0 & \text{otherwise}
\end{cases}
$$
This is to say that you will be rewards $1$ if you are at goal, and got half of the previous layer when you are stepping away from goal.

This is the same as to say:
$$
r_G(s) = \frac{1}{2} r_G(s’)\text{ if } arc(s,s’)\text{ and } d_G(s’)<d_G(s)
$$
Rewards looking ahead
We are trying to give a state with a new reward function $H$.
Firstly, we say the state $s$ has an initial reward value,
$$
H_0:=\delta_G(s)
$$
Then, we update the reward from one state to the next layer of neighborhood:
$$
H_{n+1}:= \delta_G(s)+\frac{1}{2}\max{H_n(s’)|arc_=(s,s’)}
$$
$arc_=$ encodes move/rest
$arc_=(s,s’)\leftrightarrow arc(s,s’)\text{ or }s=s’$
If $s\in G_0$ (that is $s$ in the goal set, and we starts from $s$),
$$
H_{n+1} (s) = \delta_G(s) + \frac{1}{2}H_n(s)=1+\frac{1}{2}H_0(s)
$$
If we try to conclude $H_n$ with a geometric series $a_n$, and $H_{n+1}=a_{n+1}$, we will get
$$
a_n := \sum^n_{k=0} 2^{-k} =2(1-2^{-(n+1)})
$$
If our state $s$ starts from $G_{k+1}$, and trying to get closer to a new state $s’ \in G_k$ (if there exists $arc(s,s’)$)
$$
H_{k+n+1}(s)=\frac{1}{2}H_{k+n}(s’)
$$
because $\delta_G(s)$ is $0$ in this case!
And $lim_{n\rightarrow\infty}H_n(s)=2r_G(s)$.
//why?
Heuristic
We define a function $H$ that is determined as $H=lim_{n\rightarrow \infty}H_n$.
$$
H_{n+1}= \delta_G(s)+\frac{1}{2}\max{H_n(s’)|arc_=(s,s’)}
$$
A foolproof (easy) way of heuristic for the shortest solution:
Frontier = [Hd|Tl]
With $H(Hd) \geq H(s)$ for all $s$ in Tl.
E.g.: Assume we have 4 states, A,B,C, and the goal G.
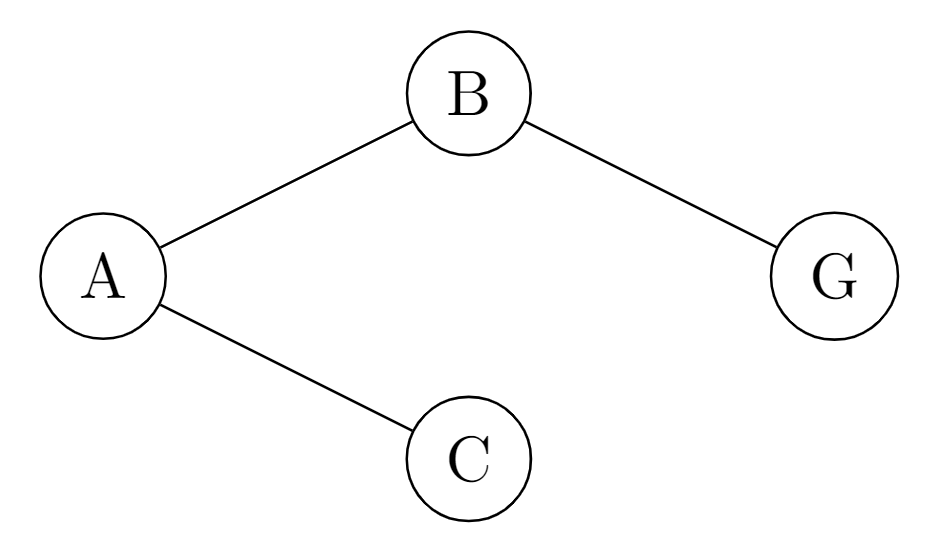
And we suppose: $\delta_G(A)=\delta_G(B)=\delta_G(C)=0$, while $\delta_G(G)=1$
If we start from $A$:
| $n=0$ | $n=1$ | $n=2$ | $n=3$ | |
|---|---|---|---|---|
| $H_n(A)$ | 0 | =$\delta(A)+\frac{1}{2}\max{H_0(B)+H_0(C)}=0$ | =$\delta(A)+\frac{1}{2}\max{H_1(B)+H_1(C)}=0+0.25=0.25$ | 0.25 |
| $H_n(B)$ | 0 | =$\delta(B)+\frac{1}{2}\max{H_0(G)}=0.5$ | =$\delta(B)+\frac{1}{2}\max{H_1(G)}=0.5$ | 0.5 |
| $H_n(C)$ | 0 | =$\delta(C)+\frac{1}{2}\max{}=0$ | =$\delta(C)+\frac{1}{2}\max{}=0$ | 0 |
| $H_n(G)$ | 1 | 1 | 1 | 1 |
If arcs have different costs, we try to extend $\delta_G(s)$ to arc/rest, $s$, $s’$, as $Q_0(s,s’)$.
which is defined as:
$$
Q_0(s,s’):=\begin{cases}
1 & \text{if } s=s’=G \
-cost(s,s’) & \text{else if }arc(s,s’)\-\max_{s1,s2}cost(s_1,s_2) & \text{otherwise} \
\end{cases}
$$
- if $s$ and $s’$ are all in the goal set, then $Q_0$ is 1;
- if there’s an arc between $s$ and $s’$, the reward is $-cost(s,s’)$ (as the price you paid for the movement)
- otherwise it takes the maximum cost from all movements(?)
And for iteration, $H_{n+1}(s,s’)$ is updated as
$$
Q_{n+1}(s,s’)=Q_0(s,s’)+\frac{1}{2}\max{Q_n(s’,s”)|arc_=(s’,s”)}
$$
E.g.:
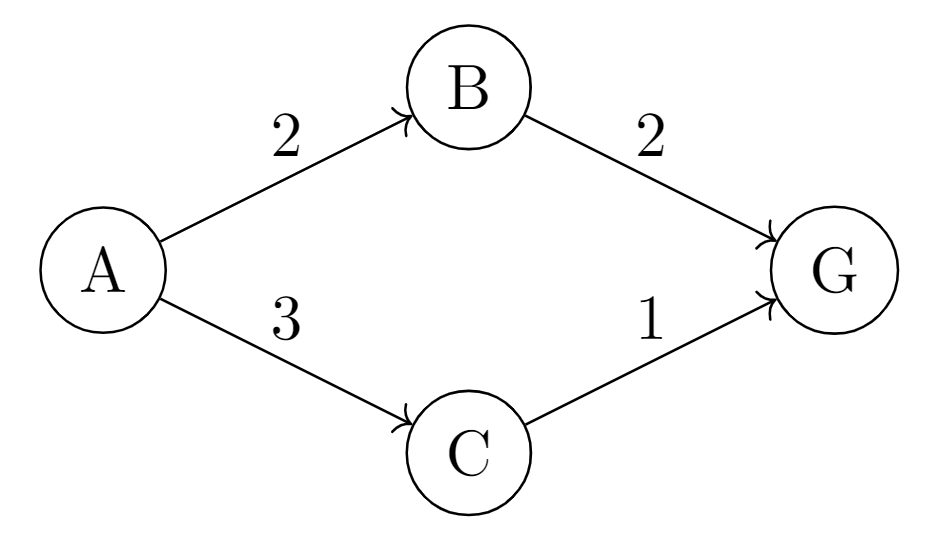
For $Q_0$:
- $Q_0(G,G)=1$ (first case in definition)
- $Q_0(A,B)=-cost(A,B)=-2$ (second case in definition)
- $Q_0(A,C)=-cost(A,C)=-3$
- $Q_0(B,G)=-cost(B,G)=-2$
- $Q_0(C,G)=-cost(C,G)=-1$
For $Q_1$:
- $Q_1(A,B)=Q_0(A,B)+\frac{1}{2}\max{Q_0(B,G)}=-2+0.5\times(-2)=-3$
- $Q_1(A,C)=Q_0(A,C)+\frac{1}{2}\max{Q_0(C,G)}=-3+0.5\times(-1)=-3.5$
- $Q_1(B,G)=Q_0(B,G)+\frac{1}{2}\max{Q_0(G,G)}=-2+0.5\times(1)=-1.5$
- $Q_1(C,G)=Q_0(C,G)+\frac{1}{2}\max{Q_0(G,G)}=-1+0.5\times(1)=-0.5$
For $Q_2$:
- $Q_2(A,B)=Q_0(A,B)+\frac{1}{2}\max{Q_1(B,G)}=-2+0.5\times(-1.5)=-2.75$
- $Q_2(A,C)=Q_0(A,C)+\frac{1}{2}\max{Q_1(C,G)}=-3+0.5\times(-0.5)=-3.25$
- $Q_2(B,G)=Q_0(B,G)+\frac{1}{2}\max{Q_1(G,G)}=-2+0.5\times(1)=-1.5$
- $Q_2(C,G)=Q_0(C,G)+\frac{1}{2}\max{Q_1(G,G)}=-1+0.5\times(1)=-0.5$
For $Q_3$: $Q_3(A,B)=-2.75$, $Q_3(A,C)=-3.25$
Discounted
(immediate) rewards $r_1, r_2, r_3, \dots$ at times $1,2,3,\dots$ give a $\gamma$-discounted value of
$$
V:=r_1+\gamma r_2 + \gamma^2 r_3 + \dots = \sum {i\geq 1} \gamma^{i-1} r_i=\left(\sum^t{i=1} \gamma^{i-1} r_i\right)+\gamma^t V_{t+1}
$$
Where $V_t$ is the value from time step $t$ on ($V_1 = V$).
$\gamma\rightarrow 0$: live in the moment, ignore the future rewards
$\gamma\rightarrow 1$: save for the future, take future as important as current
$$
V_t:=\sum_{i\geq t}\gamma ^{i-t}r_i = r_t + \gamma V_{t+1}
$$
(backward induction)
which is bound by bounds on $r_i$
$m\leq r_i \leq M$ for each $i\geq t$ implies $\frac{m}{1-\gamma}\leq V_t \leq \frac{M}{1-\gamma}$
since $\sum_{i\geq 0}\gamma ^i = (1-\gamma)^{-1}$
E.g.: Assume $\gamma = 0.9$ for the following graph. Take 2,2,3,1 as immediate rewards..
- Final state: $V(G)=0$, because there’s no future rewards from $G$.
-
State C: The only action from $C$ leads to $G$, with an immediate reward of 1.
$V(C)=r(C,G)+\gamma V(G)=1+0.9\times0=1$
-
State B: $V(B)=r(B,G)+\gamma V(G)=2+0.9\times0=2$
-
State A:
- Going to B: $V(A,B)=r(A,B)+\gamma V(B)=2+0.9\times 2=3.8$
- Going to C: $V(A,C)=r(A,C)+\gamma V(C)=3+0.9\times 1=3.9$
So we will choose the route with higher value, that is A->C.
Find Q
$Q=\lim_{n\rightarrow \infty}$
$$
Q(s,s’):=Q_0(s,s’)+\frac{1}{2}\max\left{Q(s’,s”)|arc_{=}(s’,s”)\right}$
$$
$$
Q_0(s,s’):=\begin{cases}
1 & \text{if } s=s’ \in G \
-cost(s,s’) & \text{else if }arc(s,s’)
\end{cases}
$$
Q value is used to evaluate the expected utility of taking a certain action in a specific state.
We start at:
- if $s$ is the same as $s’$ and they both in the goal set $G$, then $Q_0(s,s’)$ is 1.
- if there’s an arc between $s$ and $s’$, the Q-value is the negative cost.
E.g.: consider the following state graph, we try to calculate the shortest path from $s$ to $g$.
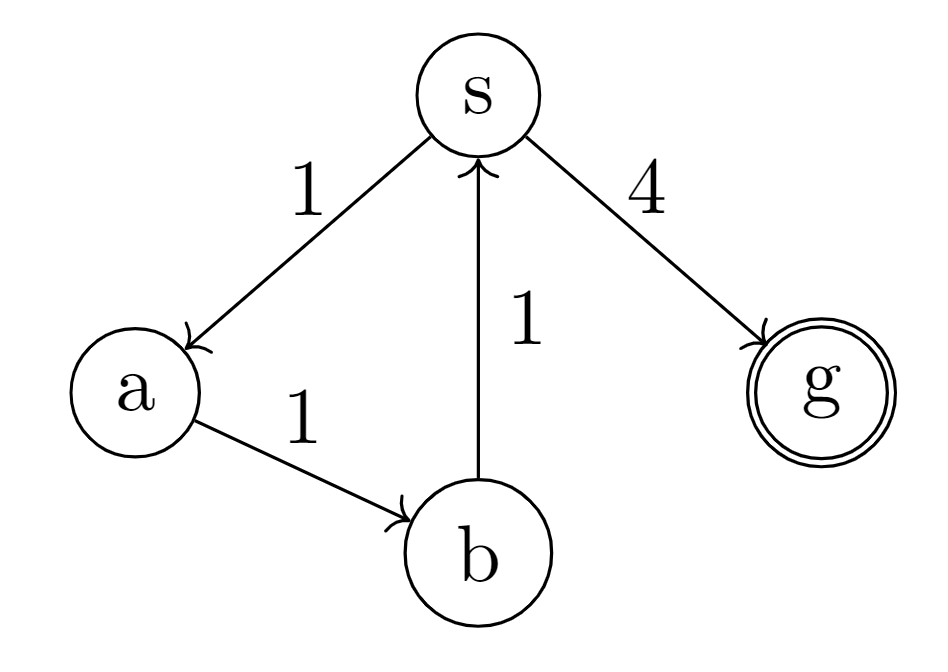
- $Q_0(g,g)=1$
- $Q_0(s,g)=-4$
- $Q(s,g)=-3, Q(a,b)=Q(s,a)=Q(b,s)=-2$
Why? Check details at: qpf Example
Raising the reward
$$
R0(s,s’):=\begin{cases}
r & \text{if } s=s’ \in G \
-cost(s,s’) & \text{else if }arc(s,s’)
\end{cases}
$$
for some reward $r$ high enough to offset costs of reaching a goal.
e.g. $r\geq 2^nnc$ for solutions up to $n-1$ arcs with arcs costing $\leq c$.
// TODO details not covered.
Recap
From node $s$, find path to goal via $s’$ maximizing
$$
Q(s,s’):= R(s,s’) + \frac{1}{2}V(s’)
$$
with discount 1/2 on future $V(s’)$.
In contrast, the cost of $s_1$ to $s_k$ is defined as:
$$
cost(s_1\dots s_k)=\sum^{k-1}{i=1}cost(s_i,s{i+1})
$$
Case of Google Page Rank

Value of webpage $P_i = probability$ a web surfer is at $P_i$ clicking links.
How it’s done?
- Initially all variables are set randomly
- move to $P_j$ from $P_i$ along link $P_i \rightarrow P_j$ probabilistically
$PR(P_5)=PR(5\ itself)+PR(4\rightarrow 5)+PR(3\rightarrow 5)=\frac{1}{5}+\frac{1}{5}\times\frac{1}{2}+\frac{1}{5}\times\frac{1}{4}=\frac{7}{20}$
Usually this is solved by iteration (see the picture above), however, we can also use a matrix so solve it:
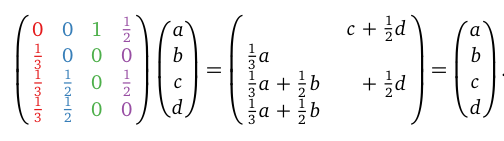
A damping factor $p$, is set for two situations when a surfer opens a webpage:
- visit a random page with $p$
- move to a new link with $1-p$
The modified matrix $A’$ is obtained by changing all elements in the row with no out-directed pages into the average. (i.e. $c_3$)
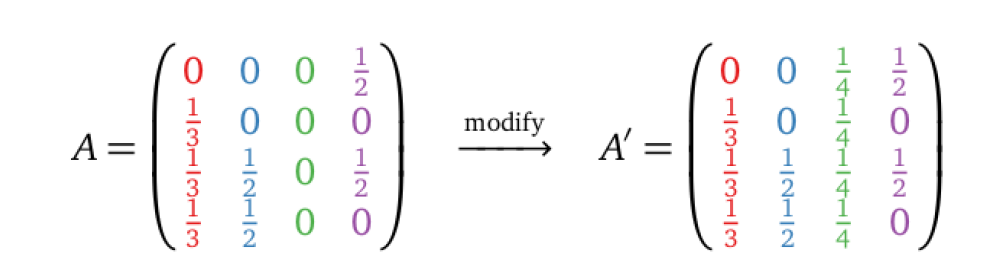
$$
M=pA+(1-p)A’
$$
Further on MDP
Given a specific $R$ of immediate rewards after particular actions calculate the return $Q$ of particular actions over time via
$$
Q = \lim {n\rightarrow \infty} Q_n\
Q{n+1}(s,s’):= R(s,s’)+\frac{1}{2}\max {Q_n(s’,s”)|arc_= (s’,s”)}
$$
Or
$$
Q_{n+1}(s,a)\approx \alpha [R(s,a)+\gamma \max{Q_n(s’,a’)|a’\in A}]+(1-\alpha)Q_n(s,a)
$$
Where the first one is the second one with action $\alpha$ resulting in $s’$ deterministically for $\alpha=1, \gamma = \frac{1}{2}$. $s’$ is learned from experience.
$\alpha$ is the learning rate.
Formal definition of MDP
a 5-tuple <S,A,p,r,$\gamma$> consisting of:
- a finite set $S$ of states $s,s’,\dots$
-
a finite set $A$ of actions $a,\dots$
-
a function $p: S\times A \times S \rightarrow [0,1]$
$p(s,a,s’)=\text{prob}(s’|s,a)=$ how probable is $s’$ after doing $a$ at $s$
$\sum_{s’}p(s,a,s’)=1$ for all $a\in A, s\in S$
-
a function $r$: $S\times A\times S \rightarrow \bold{R}$
$r(s,a,s’)=$ immediate reward at $s’$ after $a$ is done at $s$.
-
a discount factor $\gamma \in [0,1]$
Missing: policy $\pi: S\rightarrow A$ (what to do at s)
Policy from an MDP
Given state $s$, pick action $a$ that maximizes return
$$
Q(s,a):= \sum_{s’}p(s,a,s’)\left(r(s,a,s’)+\gamma V(s’)\right)
$$
The equation considers different outcomes $s’$ with the sum of $s’$; $r$ is the immediate reward and $\gamma \dots$ is the discounted future.
For $V$ tied back to $Q$ via policy $\pi:S\rightarrow A$
$$
V_\pi (s):=Q(s,\pi(s))
$$
$\pi$ decided what to do under the state of $s$.
$V_\pi(s)$ is the value of during the action decided by $\pi$ under the state of $s$.
Greedy Q
E.g. the greedy $Q-policy$ above
$$
\pi(s) := arg \max_{a} Q(s,a)
$$
for
$$
Q(s,a) = \sum_{s’} p(s,a,s’)\left(r(s,a,s’)+\gamma \max_{a’} Q(s’,a’)\right)
$$
Here, $\pi(s)$ finds the action that leads to the maximum $Q(s,a)$, which indicates the payback of doing $a$ from $s$.
Value iteration
Value iteration works on the iteration of $Q$ value, and approximates the best policy.
Focus on $Q$, approached in the limit
$$
\lim_{n\rightarrow \infty}q_n
$$
from iterates:
$$
q_0(s,a):=\sum_{s’}p(s,a,s’)r(s,a,s’)\
q_{n+1}(s,a):=\sum_{s’}p(s,a,s’)\left(r(s,a,s’)+\gamma \max_{a’} q_n(s’,a’)\right)
$$
$q_0$ is initialized as the immediate reward.
$q_{n+1}$ is the new $Q$ value when iteration goes on, which considers the best value of all $Q$s of different actions from the previous state.
Only in the case of $p(s,a,s’)=1$ for some $s’$ (that is we only have one choice only the state), the iterates simplify to
$$
q_0(s,a):=r(s,a,s’)\
q_{n+1}(s,a):=r(s,a,s’)+\gamma \max_{a’}q_n(s’,a’)
$$
Deterministic actions and absorbing states (ends)
For a state $s$ and an action $a$, the action is called $s-deterministic$ if $p(s,a,s’)=1$.
A state is absorbing if $p(s,a,s)=1$ for every action $a$, that is nothing will be changed anymore under that state. In this condition,
$$
Q(s,a)=r(s,a,s)+\gamma V(s)\
V(s)=\frac{r_s}{1-\gamma}
$$
where $r_s=\max_{a}r(s,a,s)$
Because the reward in the future is fixed, $V(s)$ is calculated as
$$
r_s + \gamma r_s + \gamma^2 r_s + \gamma^3 r_s + \cdots
$$
which is a geometric sequence,$Sum=\frac{a}{1-r}$
Hence $V(s)=\frac{r_s}{1-\gamma}$
A state $s$ is sink if is absorbing and $r(s,a,s)=m$ for all $a$.
An action is called $s-drain$ if for some sink $s’$,
$$
p(s,a,s’)=1\text{ and }r(s,a,s’)=m
$$
sink is the state that the game ends, and $s-drain$ is the action that always leads to the sink.
Let
$$
A(s):={a\in A\ |\ a \text{ is not an s-drain}}
$$
so if $A(s)\neq \phi$,
$$
V(s)=\max{Q(s,a)\ |\ a \in A}=\max{Q(s,a)\ | \ a\in A(s)}
$$
That is, $V(s)$ is the action with maximum $Q$ value, from all actions that does not leads to the sink.
Deterministic MDP
($p \in {0,1}$)
Given $arc$ and goal set $G$, let
$$
A={s\ |\ (\exist s’) arc_= (s’,s)} = S
$$
where for each $a\in A$,
$p(s,a,s’)=1$ if $a=a’$ and $arc_=(s,s’)$, otherwise $p=0$
$r(s,a,s’)=R(s,s’)$ if $a=s’$ and $arc_=(s,s’)$ otherwise it could be anything
Satisfy prob constraint $\sum_s’ p(s,a,s’)=1$ via sink state $\perp \notin A$, requiring of every $a\in A$ and $s\in S$,
$p(s,a,\perp)=1$ if not $ arc_=(s,a)$
$p(\perp,a,s)=1$ if $s=\perp$
$r(s,a,\perp)=$ min reward
MDP Calculation Example
consider the graph we mentioned [before](#Find Q):
Basic rules:
$$
Q_{n+1}(x,y):=Q_0(x,y)+\frac{1}{2}\max{Q_n(y,z)\ |\ arc_=(y,z)}
$$
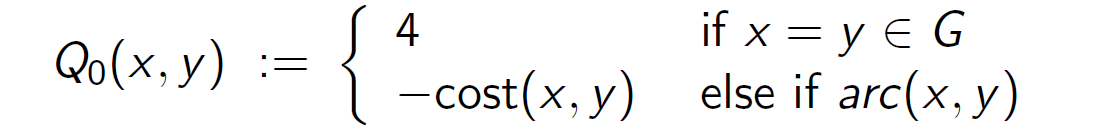
The iteration goes as:
$n=0$:
$Q_0(s,a)=-\text{cost}(s,a)=-1$
$Q_0(s,g)=-\text{cost}(s,g)=-4$
$Q_0(a,b)=-\text{cost}(a,b)=-1$
$Q_0(b,s)=-\text{cost}(b,s)=-1$
$Q_0(g,g)=4$
$n=1$:
$Q_1(s,a)=Q_0(s,a)+\frac{1}{2}Q_0(a,b)=-1+\frac{1}{2}(-1)=-\frac{3}{2}$
$Q_1(s,g)=Q_0(s,g)+\frac{1}{2}Q_0(g,g)=-4+\frac{1}{2}(4)=-2$
$Q_1(a,b)=Q_0(a,b)+\frac{1}{2}Q_0(b,s)=-1+\frac{1}{2}(-1)=-\frac{3}{2}$
$Q_1(g,g)=Q_0(g,g)+\frac{1}{2}Q_0(g,g)=4+\frac{1}{2}(4)=6$
$n=2$:
$Q_2(s,a)=Q_0(s,a)+\frac{1}{2}Q_1(a,b)=-1+\frac{1}{2}(-\frac{3}{2})=-\frac{7}{4}$
$Q_2(s,g)=Q_0(s,g)+\frac{1}{2}Q_1(g,g)=-4+\frac{1}{2}(6)=-1$
$\cdots$
In this way we can say that, at state $s$, the best choice is to:
when $n=0$, choose $a$; $n=1$, choose $a$; $n=2$, choose $g$.
Example on exercise
Sam is either fit or unfit
$$
S={fit, unfit}
$$
and has to decide whether to exercise or relax
$$
A={exercise, relax}
$$
$p(s,a,s’)$ and $r(s,a,s’)$ are $a$-table entries for row $s$, col $s’$
Exercise Fit Unfit fit .99, 8 .01, 8 unfit .2, 0 .8, 0
Relax Fit Unfit fit .7, 10 .3, 10 unfit 0, 5 1, 5 Entries of unfit columns follow from assuming immediate rewards do not depend on the resulting state, and
$$
\sum_{s’}p(s,a,s’)=1
$$
$$
q_0(s,a):=p(s,a,fit)r(s,a,fit)+p(s,a,unfit)r(s,a,unfit)
$$
$$
V_n(s):=\max(q_n(s,excercise),q_n(s,relax))
$$
$$
q_{n+1}(s,a):=q_0(s,a)+.9(p(s,a,fit)V_n(fit)+p(s,a,unfit)V_n(unfit))
$$
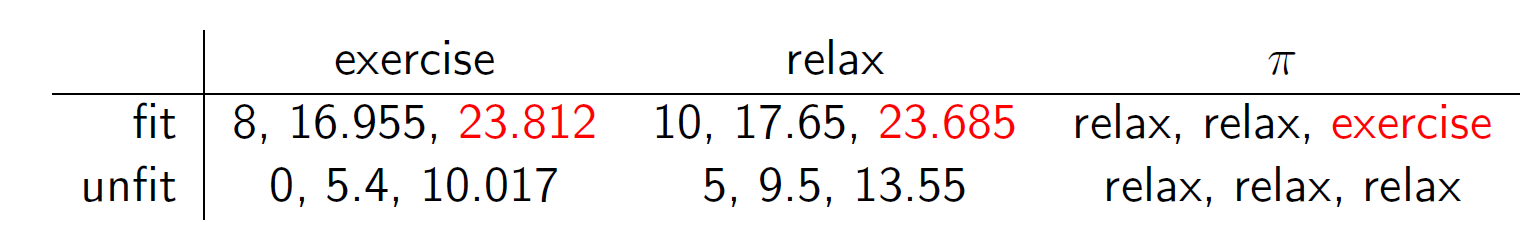
Temporal difference (TD)
A sequence of values $v_1,v_2,v_3,\cdots$, averages at time $k$ to
$$
A_k := \frac{v_1+\cdots+v_k}{k}
$$
which learning $v_{k+1}$ updates to
$$
A_{k+1} = \frac{v_1 + \cdots + v_k + v_{k+1}}{k+1}=\frac{k}{k+1}A_k + \frac{1}{k+1}V_{k+1}
$$
so if $\alpha_k=\frac{1}{k}$,
$$
A_{k+1}=(1-\alpha_{k+1})A_k + \alpha _ {k+1} v_{k+1}=A_k + \alpha {k+1}(v{k+1}-A_k
)
$$
Q learning
Q learning tells agent the best option to do under different circumstances.
Assume $v_{k+1}$ is derived from $r_{k+1}$, $s_{k+1}$, observed sequentially
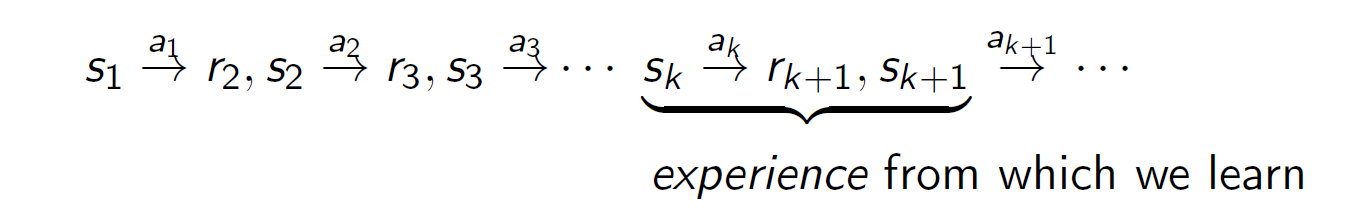
$$
v_{k+1}:=r_{k+1}+\gamma \max_{a} Q_k (s_{k+1},a)
$$
given $0\leq \gamma < 1$, $Q_1: (S\times A)\rightarrow R$ and $v_1\in R$, with
$$
Q_{k+1}(s_k,a_k):= (1-\alpha)Q_k(s_k,a_k)+\alpha v_{k+1}
$$
for $0\leq \alpha \leq 1$,
$$
A_{k+1}=(1-\alpha_{k+1})A_{k}+\alpha_{k+1}v_{k+1}
$$
for $\alpha_{k+1}=\frac{1}{k+1}$ from previous slide.
Terminating search
We set a timeout limit of search to avoid infinite loop.
bSearch(Node,_) :- goal(Node).
bSearch(Node,Bound) :- arc(Node,Next), tick(Bound,Less), bSearch(Next,Less).
search(Start) :- bound(Start,Bound), bSearch(Start,Bound).
tick is used to manage loops, which should decrease value after each search step and terminates the loop in the end. There’s no infinite sequence x1, x2, ..., for $tick(x_i,x_{i+1})$ for every integer $i>0$
P vs NP
$P \ne NP$ means non-determinism wrecks feasibilty
$P=NP$ means non-determinism makes no difference to feasibility
Boolean satisfiability (SAT)
Given a Boolean expression $\phi$ with variables $x_1, …, x_n$, by assigning True/False to $x_1,…,x_n$, we make $\phi$ true.
This is a NP problem.
Cook-Levin Theorem: SAT is in $P$ if $P = NP$.
3 different SAT problems: CSAT, k-SAT, Horn-SAT
Constrain Satisfaction Problem
- a list of variables, $Var = [X_1, …, X_n]$
- a list of dominants, $Dom = [D_1, …, D_n]$
- a finite set of constraints
E.g. SAT: $D_i={0,1}, s_i=2$ for search space of size $2^n$
Problem: the purpose of CSP is to find a way of initializing the variables to satisfy the requirement.
# The variables are not set before trying to answer if X\=Y, so the answer is no.
| ?- X\=Y, X=a, Y=b.
no.
# X and Y are already different before the query, so the answer is definitive.
| ?- X=a, Y=b, X\=Y.
X = a, Y = b
Order-independent unification
Input: set $\mathcal{E}$ of pairs $[t,t’]$
Output: substitution $[[X_1,t_1],\cdots,[X_k,t_k]]$ unifying pairs in $\mathcal{E}$
Simplify $\mathcal{E}$ non-deterministically until no longer possible
Rules of simplification:

Instantiate before negating (as failure)
p(X) :- \+q(X), r(X).
q(a). q(b).
r(a). r(c).
| ?- p(X).
false.
| ?- p(c).
true.
===================
p(X) :- \+q(X).
q(X) :- \+r(X).
r(c).
| ?- p(X).
true.
| ?- p(a).
false.
Generate and test
The way how to systematically search an answer set for given constraints.
Search tree Interleave generation with testing + backtacking
Datalog
Formal semantics
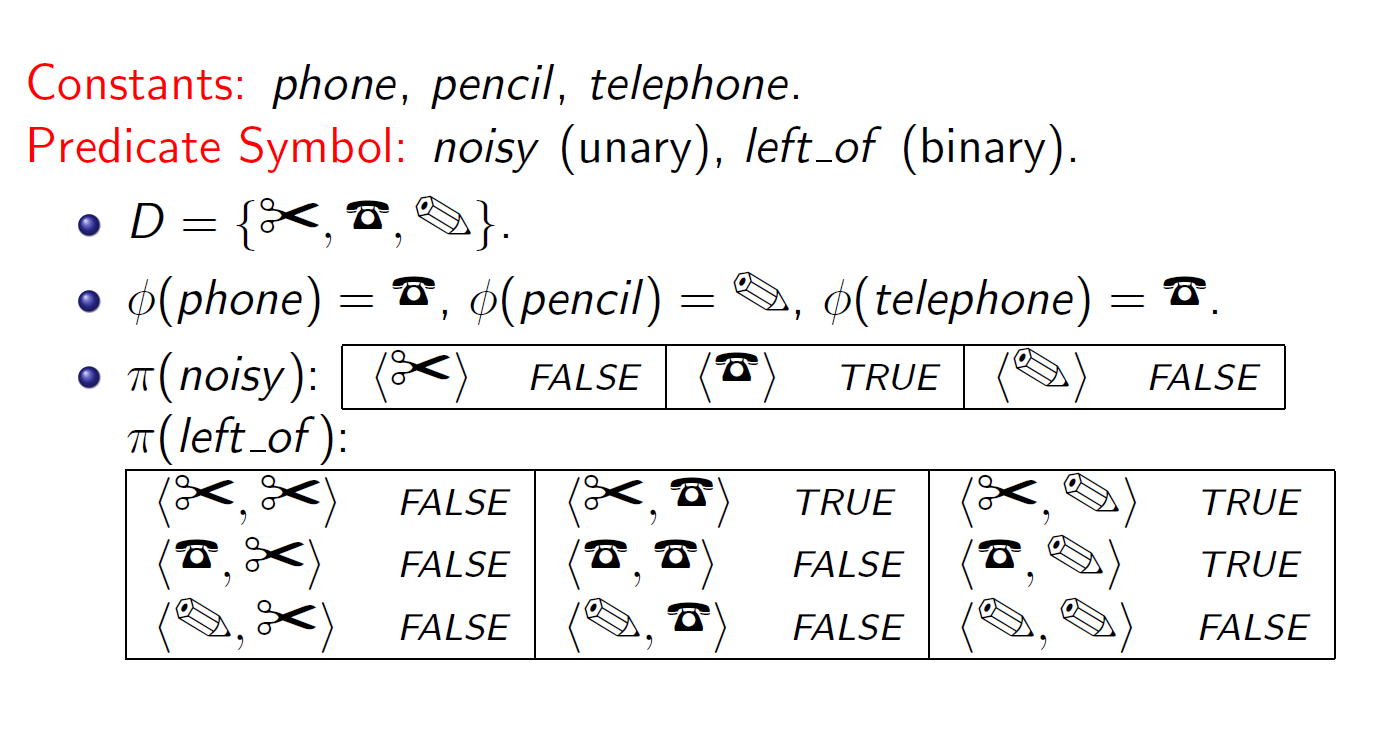
An interpretation is a triple $I=<D,\phi,\pi>$
$D$: Domain
$\phi$: a mapping that assigns to each constant an element of $D$. Constant $c$ denotes individual $\phi(c)$.
$\pi$:a mapping that assigns to each n-ary predicate symbol a relation.