本文发布于 1887 天前。
UTF-8中的字符数
当字节数为1时,首字节范围:0000 0000-0111 1111,即0-127
当字节数为2时,首字节范围:1100 0000-1101 1111,即192-223
当字节数为3时,首字节范围:1110 0000-1110 1111,即224-239
当字节数为4时,首字节范围:1111 0000-1111 0111,即240-247
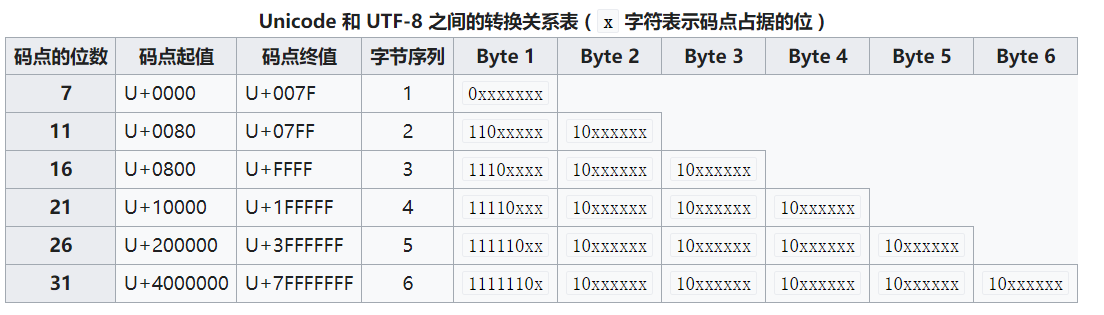
因此,当全部的内容为中文时,可以暂且认为:一个汉字占三个字节。
string.sub的定义和用法
字符串截取使用 sub() 方法。
string.sub() 用于截取字符串,原型为:
string.sub(s, i [, j])
其中,s为原始字符串,i和j为开始和结束截取的字节位置。j默认为-1,即最后一个字符。
line.text_stripped
line.text_stripped函数可以在Aegisub中调出当前句截取标签后的完整文字。
纯汉字截取
Comment: 0,0:00:00.00,0:00:05.00,Default,,0,0,0,code once,c = -1 tab={}
Comment: 0,0:00:00.00,0:00:05.00,Default,,0,0,0,code syl,c = c+1 tab[c]=string.sub(line.text_stripped,(c-1)*3+1,(c-1)*3+3)
Comment: 0,0:00:00.00,0:00:05.00,Default,,0,0,0,template char,!c! !tab[c]! 原始字:
Comment: 0,0:00:00.00,0:00:05.00,Default,,0,0,0,karaoke,{\k1}你{\k1}的{\k1}声{\k1}音{\k1}不{\k1}能{\k1}忘{\k1}记
定义了一个空表tab,c从-1开始,用于计数字符。